
The project focuses on analyzing 2 datasets. Each dataset contains information such as the Video ID, Comments for each video ID, views, number of likes and replies. The goal was to create a function which reads through the “comment_text” column and returns a sentiment analysis ranging from 0 to 1.
To address this challenge, different Python libraries were used such as:
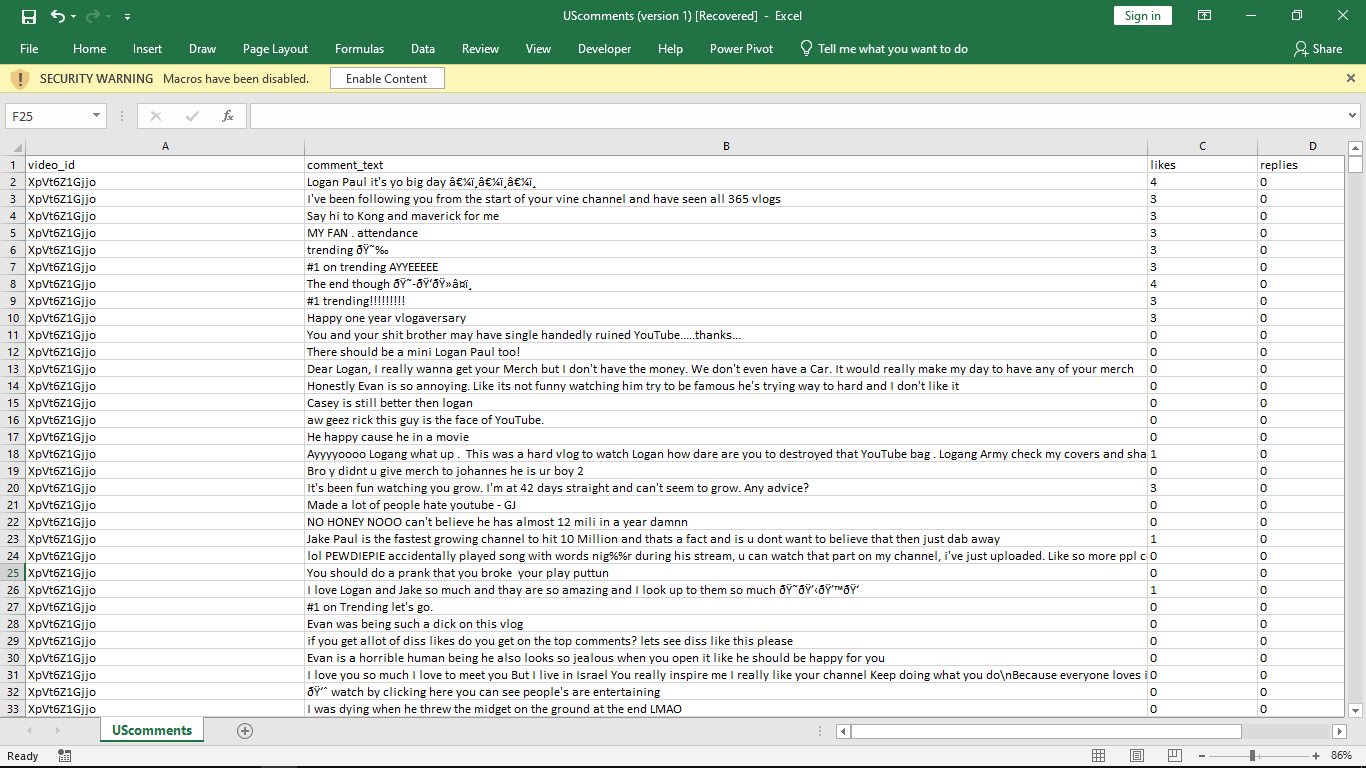
Extracted Dataset from YouTube A
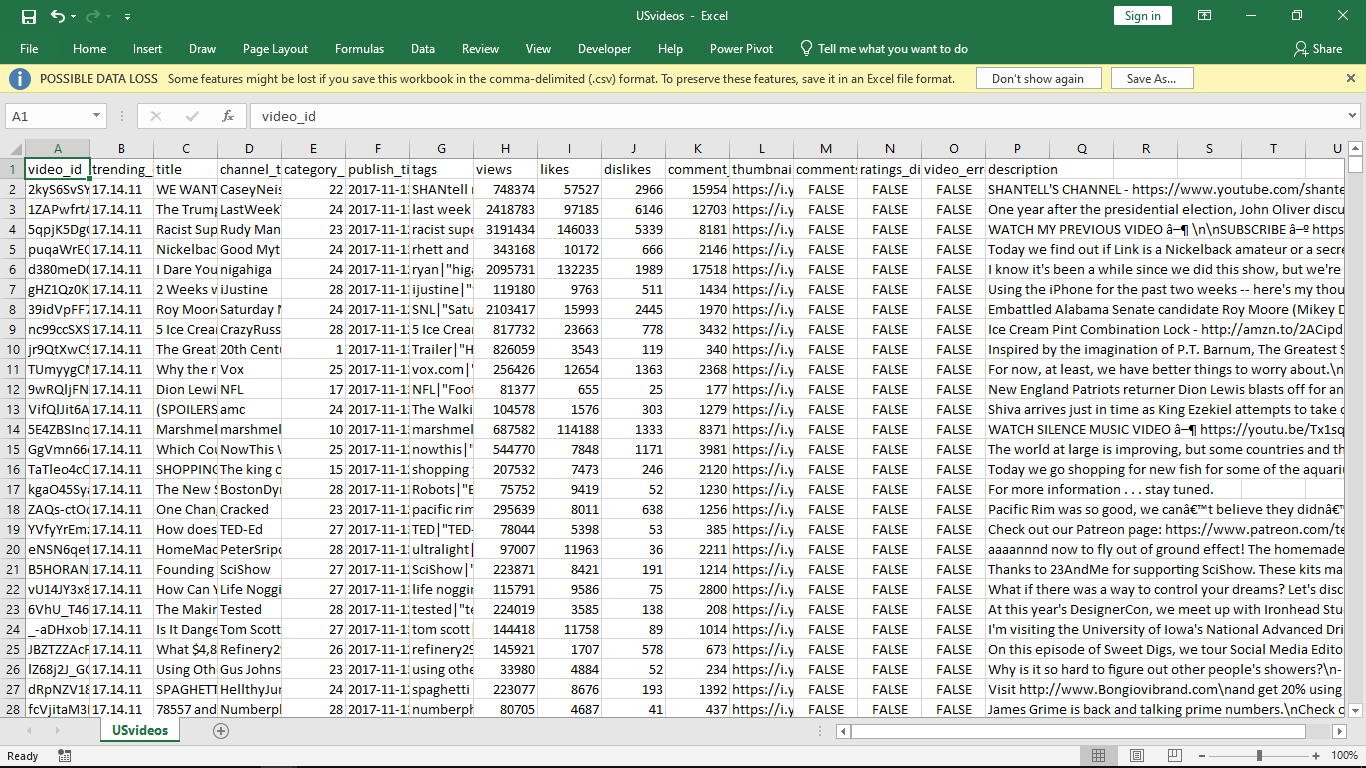
Extracted Dataset from YouTube B
Project Preview
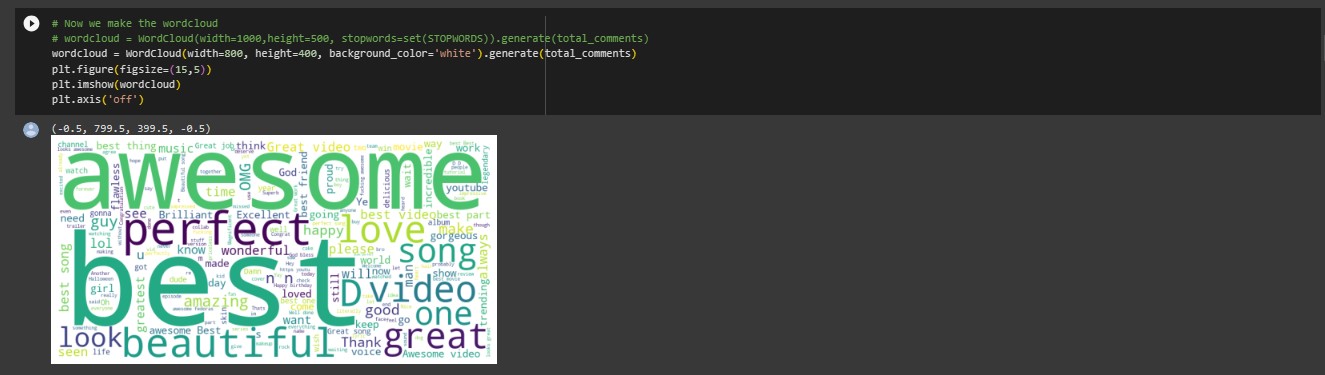
WordCloud for Positive Keywords
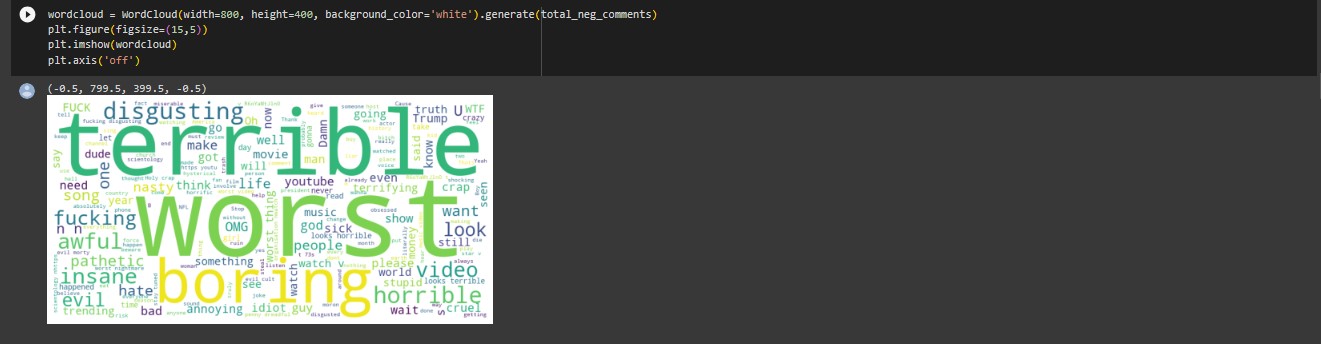
WordCloud for Negative Keywords
Based on the wordcloud chat, we were able to confirm that some of the most used positive words used in the comments includes (Best, Awesome, Perfect, Beautiful, Great Love, etc.). We were also able to confirm that some of the most used negative words were (Terrible, Worst, Boring, Disgusting, etc.).
For this, we employed the use of regression analysis to determine the relationship between the parameters. We began by identifying the independent and dependent variables in out parameters.
Dependent Variable (Y) – Views
Independent Variable (X) – Likes & Dislikes
Each column consisted of continuous variable hence there wasn’t a need to convert the data into dummy variables. We began by isolating only the needed columns (Views | Likes | Dislikes)
We followed by running a CORRELATION MATRIX on the 3 columns to identify any similarities that existed between the dependent and Independent variable.
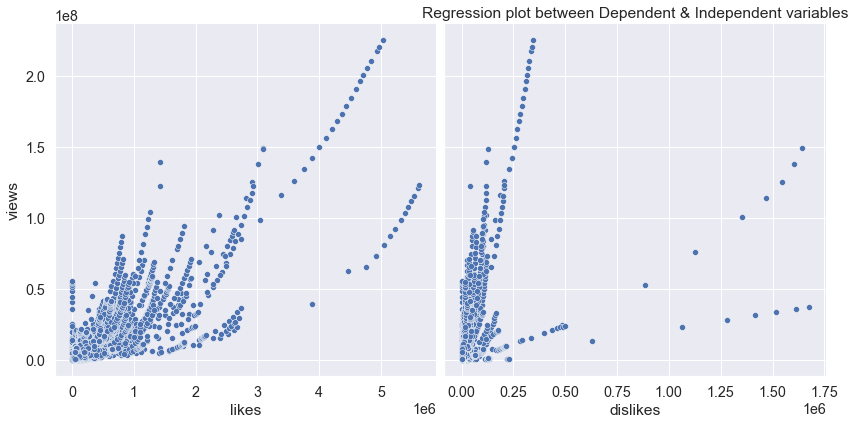
Pairplot Chart between Dependent & Independent Variables
We were able to conclude that there was a greater relationship between Views and Likes (85%) compared to the relationship which existed between Views and Dislikes (47%).
We also plotted a regression graph to identify the amount of relationship that exists between the results and a similar inference was obtained.
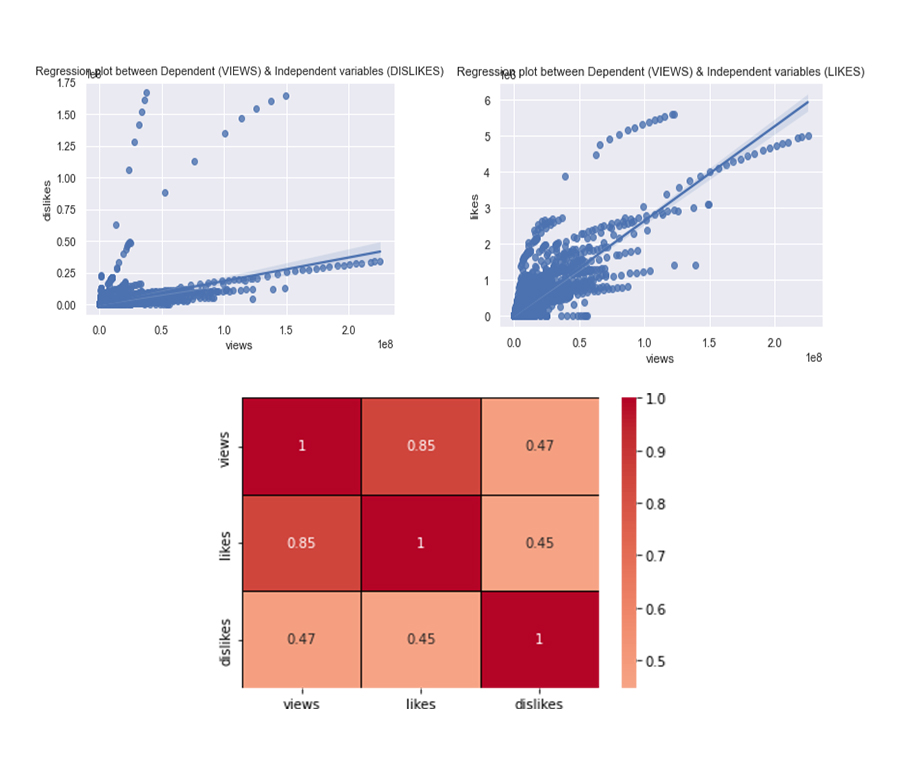
Regression Plot & Correlation Matrix Chart
See Full Code on Google Colaboratory.
See Case Study on Github.
I'm happy to connect, listen and help. Let's work together and build something awesome. Let's turn your idea to an even greater product. Email Me.